1.はじめに
このページは,2011年10月号の映像情報メディア学会誌の「てれび・さろん」に掲載された解説記事「データマイニングツールWeka」のサポートページです.
Wekaは,ワイカト大学(ニュージーランド)の機械学習研究グループが中心となって開発されているオープンソースのデータマイニングツールです.
記事中でもインストール方法を紹介してありますが,インストール時に確認すべき事項は以下の通りです.
- OSの種類
- Java(Oracle版)のインストールの有無
OSがWindowsの場合は,Javaの実行環境(JRE)付のパッケージもありますので,JREがインストールされていなくてもWekaを利用することができます.
Mac OS Xの場合は,Javaの実行環境がインストールされていることを確認して,専用のパッケージによりインストールが可能です.
その他,OSを問わずZIP形式のアーカイブファイルが用意されています.システムへのインストール権限が無い場合などにも,Javaの実行環境が用意されていれば,このZIPファイルを展開することでWekaが利用できます.
以上のうち,各自の環境にあったファイルをDownloadのページからウンロードし,インストールあるいは展開します.
2.記事中の例題を用いた実行例
記事中の解説で用いた例題ファイルは,UCI機械学習データセットレポジトリから取得したファイルを一部加工した(クラスに当たる項目を最後の列とした)ものです.
- 例題入力ファイル(letter.csv)
この入力ファイルに対して,決定木学習アルゴリズムC4.5の実装であるJ4.8をコマンドラインから適用するのが本例題の内容です.CSVファイルを入力として,数値属性と誤認された属性の修正(NumericToNominalフィルタによる),決定木学習の実行,分類予測結果(シリアライズされたモデル,予測結果付ファイル)の保存を行います.
また,以上の実行の流れをKnowledge Flowでも実行が可能です.実行画面は図1のようになります.Knowledge Flowでは,処理に対応するアイコンを上部のパネルから選択し,フローレイアウト(Flow Layout)でもう一度クリックして配置します.処理同士の接続は,各アイコンを(右)クリックして次の処理に入力する出力を→として接続していきます.連続的な画面で説明したKnowledge Flowの使い方に関しては,本サイトの解説をご覧下さい.
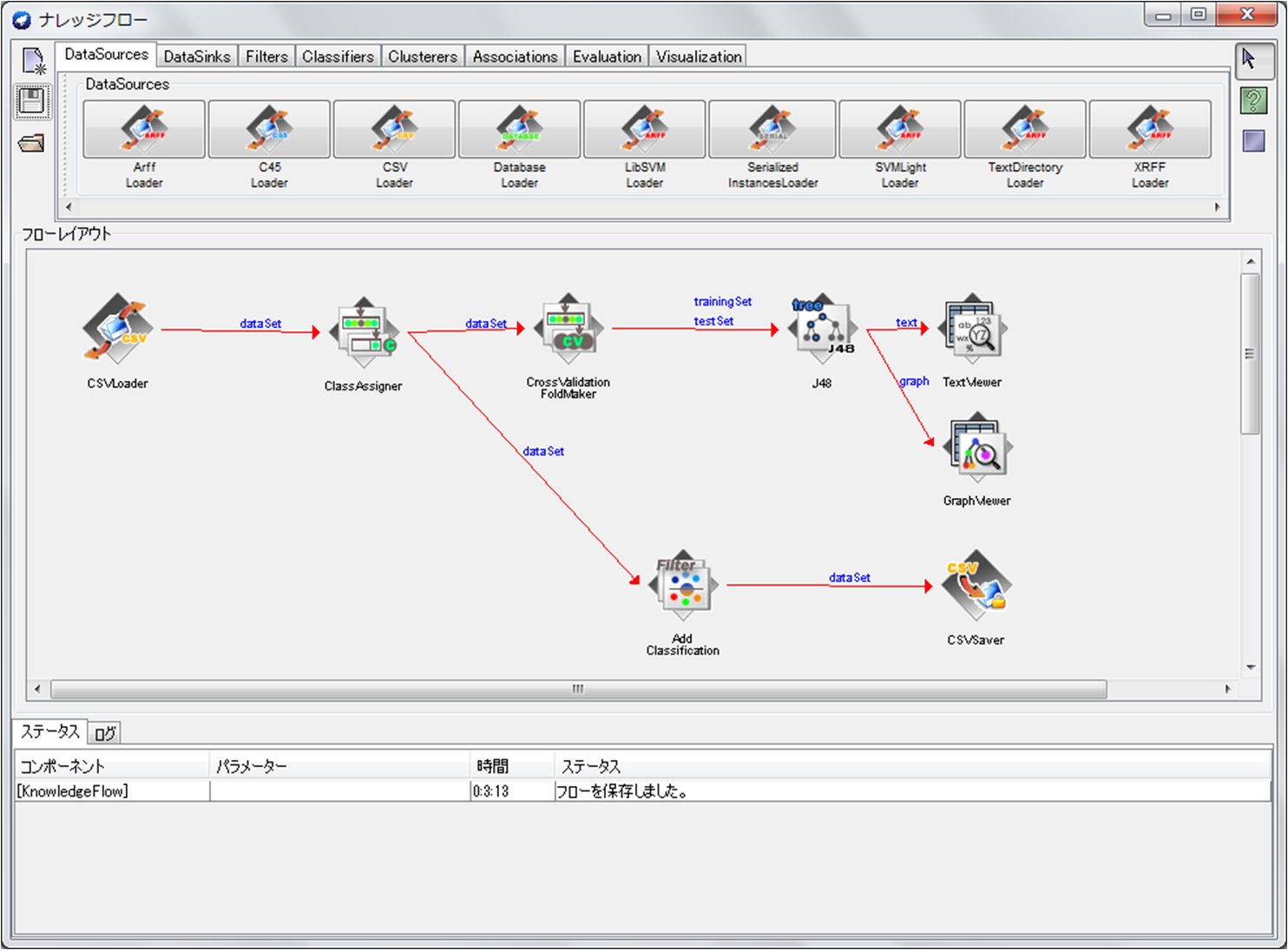
図1:Knowledge Flowによる例題の実行(クリックで拡大)
※Weka(ver.3.6.5)以降でメニューが日本語化されている場合,環境によって日本語フォントが表示されないこともあります.
3.Explorerでのデータ視覚化
WekaのGUIであるExplorerでは,ファイルを読み込むだけでデータの内容の視覚化が可能です.
前処理(Preprocess)パネルでは,開いたファイルの情報,各属性の情報が視覚化されます.各属性の内容は,左下部のリストからそれぞれの属性を選択することにより,右下部に基本統計情報とヒストグラムが表示されます.
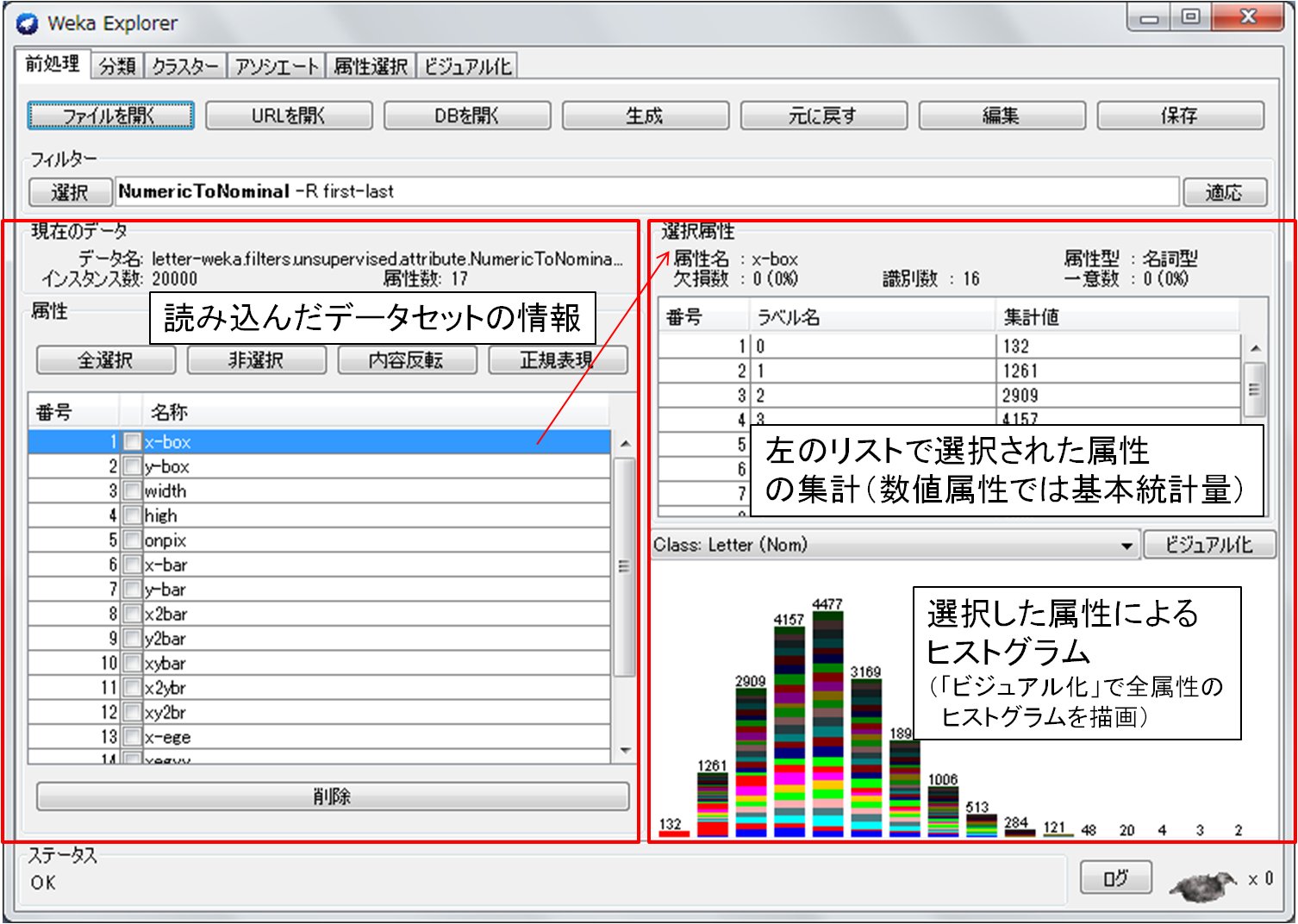
図2:Explorer前処理(preprocess)パネルでの視覚化例(クリックで拡大)
さらに,ビジュアル化(Visualization)パネルでは,属性の全ペア同士の散布図(図3)が表示されます.各散布図の大きさやプロットの大きさについては,散布図の下にあるスライダで調整し,更新ボタンを押すことで反映されます.また,それぞれの散布図をクリックすると,図4のように対象のペアでの散布図を大きく詳細に表示することが可能です.各プロット(点)はデータに対応しているため,ダブルクリックにより1データに至るまで詳細に調べることも可能です.
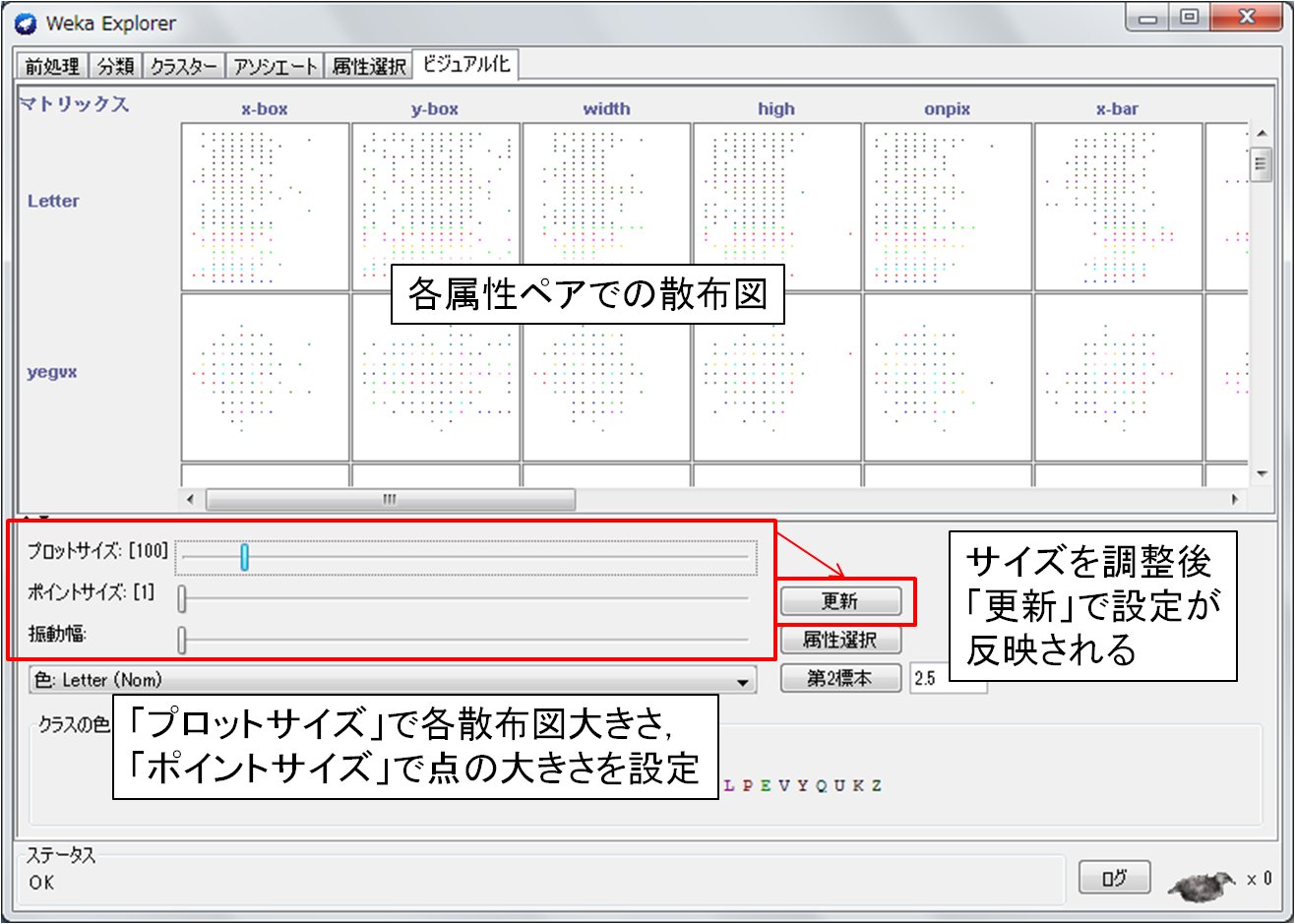
図3:視覚化(visualization)パネルによるデータの視覚化例(クリックにより拡大)
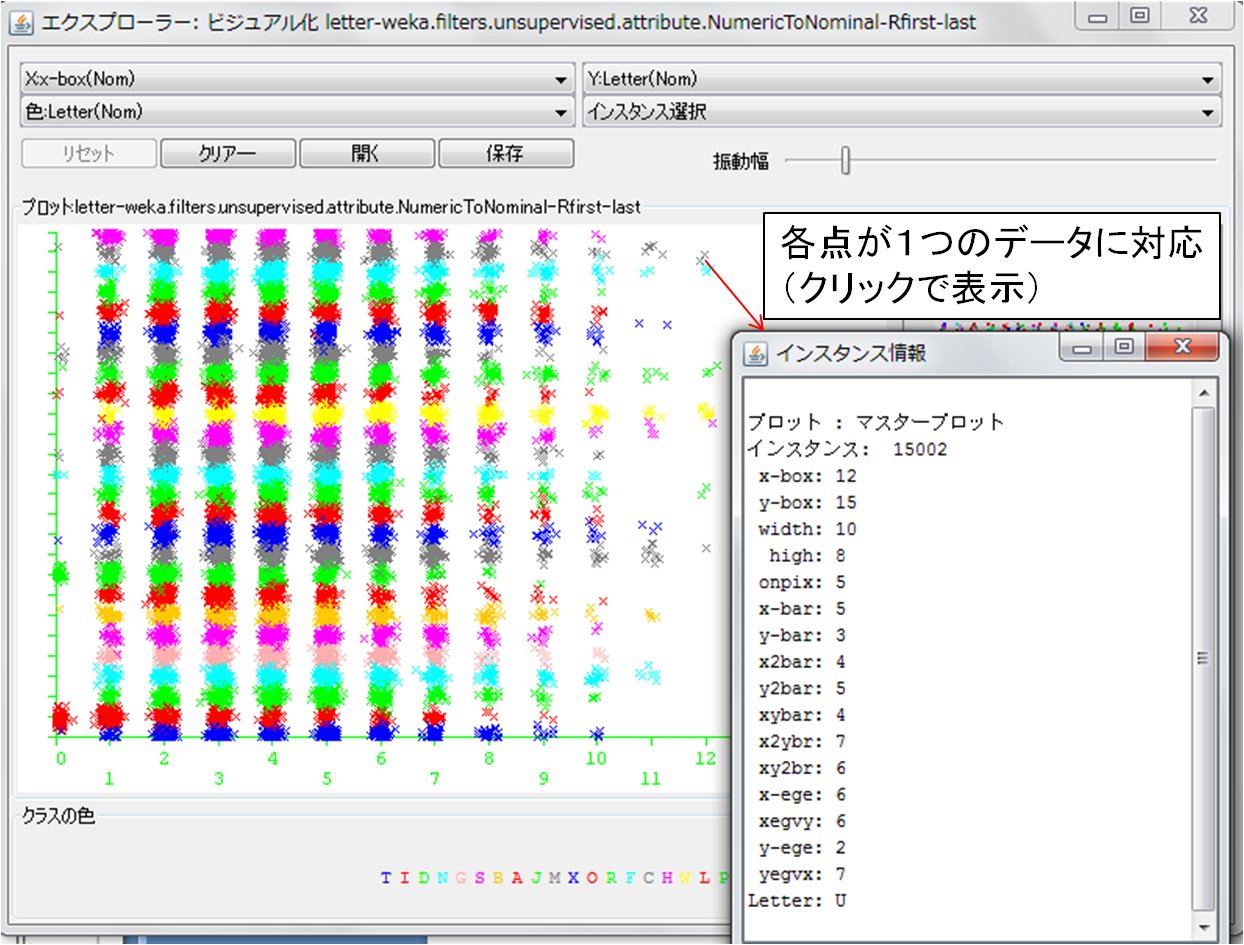
図4:Wekaの散布図によるデータの視覚化(クリックにより拡大)
5.リンク集
Wekaをマイニング処理機能として利用可能なツール:
- KNIME | Konstanz Information Miner. http://www.knime.org/.
- RapidMiner http://rapidminer.com/.
- Pentaho. http://www.pentaho.com/.
データマイニングに関する情報,性能評価用の共通データセットに関するWebページ:
- KDNuggets. http://www.kdnuggets.com/.
- University of California, School of Information and Computer Science. UCI Machine Learning Repository. http://archive.ics.uci.edu/ml/index.html.
Wekaを映像データに適用した事例: